ADAAS Insights
Building a Question-Answer AI Tool: Do You Need to Train Your Own Model?
Discover the process of building a question-answer AI tool and explore whether training your own model is necessary. Learn about pre-trained models, data collection, fine-tuning, and evaluate the trade-offs to make an informed decision.

Introduction
Building a question-answer AI tool can revolutionize information retrieval and enhance user experiences. However, one common question arises: Do you need to train your own model for this task? In this article, we will delve into the process of developing a question-answer AI tool and explore whether training a custom model is essential or if pre-trained models can suffice. By understanding the nuances and trade-offs involved, you can make an informed decision that aligns with your project goals and available resources.
Pre-Trained Models for Question-Answering
Pre-trained models, such as BERT and GPT, provide a powerful starting point for developing a question-answer AI tool. These models have been trained on extensive datasets, enabling them to understand language and perform well in various tasks. By utilizing pre-trained models, you can benefit from their broad knowledge base and leverage their capabilities for your specific application. Additionally, fine-tuning techniques allow you to customize the pre-trained model using your own data, making it unique to your needs. Data organization, including the use of vector DBs, can further enhance the efficiency and effectiveness of pre-trained models in question-answering tasks.
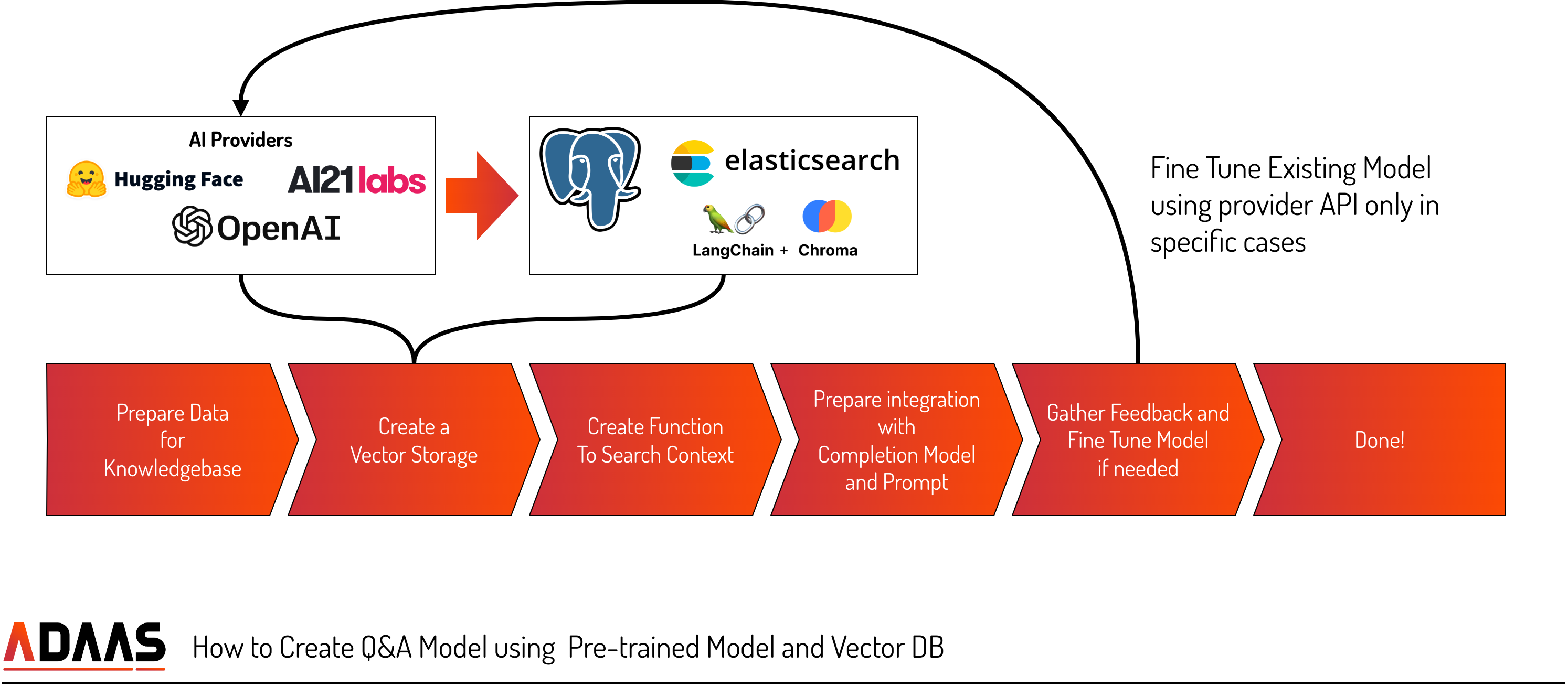
- Data Collection
To build a question-answer AI tool using pre-trained models, data collection plays a crucial role. This involves gathering a diverse range of information that will serve as the knowledge base for your solution. Whether it's video files, manuals, text documents, or internal resources, the collected data will be used to generate accurate and relevant answers to user questions. A comprehensive and well-curated dataset ensures that your AI tool has access to the necessary information to provide valuable responses. - Vector Storage
In order to efficiently retrieve and process textual information, a vector storage approach can be employed. This method involves representing text as vectors comprising multiple parameters. Libraries or AI models like OpenAI's embedding model can be used to convert text into vectors. By storing text as vectors, you enable fast full-text searches that take into account various factors derived from user questions. This vector-based storage enhances the relevance and accuracy of the retrieved information. - Search
Implementing an effective search algorithm is vital for querying the collected data. Depending on the size and complexity of your dataset, various tools and technologies can be employed, ranging from PostgreSQL to Elasticsearch. The search algorithm should be optimized and tuned to ensure fast and accurate retrieval of relevant information. This optimization process can involve indexing, ranking, and filtering techniques to enhance search results and improve the overall user experience. - Completion
Once the relevant data is identified, the next step is to generate human-like answers. Language Models (LLM) excel at understanding context and generating coherent responses. By providing relevant search results and creating a completion using a prompt, such as
"Act as a Sales expert from company [ABC] to answer the question: [QUESTION] based on the context: [CONTEXT],"
the AI tool can generate comprehensive and contextually appropriate answers. Fine-tuning the LLM models with business-specific data can further enhance the accuracy and relevance of the generated responses. - Fine-Tuning
To incorporate your business-specific nuances and improve the performance of the pre-trained models, fine-tuning can be applied. However, it is essential to collect the right feedback and inputs to ensure the models receive valid and appropriate training data. By fine-tuning the models using relevant and high-quality data, you can tailor the AI tool to better align with your business needs and deliver more accurate responses. - Feedbacks
Continuously improving the question-answer solution requires gathering user feedback on the generated answers. Providing a feedback mechanism allows users to report any issues or provide suggestions for improvement. Solutions like prst.ai and Humanloop enable the collection of user feedback from the outset. Leveraging user feedback helps identify areas of improvement, refine the AI tool's performance, and ensure its relevance and usefulness in real-world scenarios.
Completely Custom Self-Trained Model
In this section, we will explore the process of building a completely custom self-trained model for question-answering. This approach involves data organization, filtering, training and test sets, and the selection of appropriate model architectures.
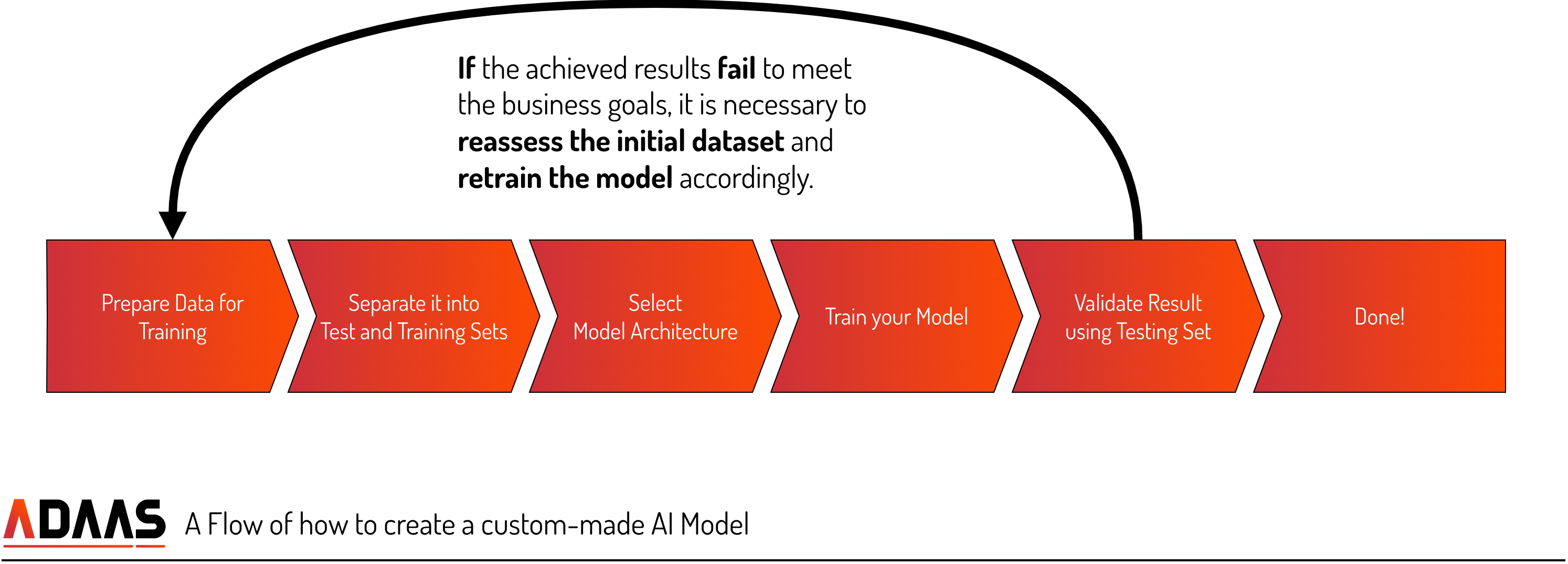
- Data Organization and Filtering
When building a completely custom self-trained model for question-answering, data organization is crucial. You need to gather a diverse and relevant dataset that covers various topics related to the domain you want your AI tool to specialize in. Additionally, data filtering becomes essential to ensure the quality and accuracy of the training data. Removing noise, irrelevant information, or biased content helps in training a more reliable and unbiased model. - Training and Test Sets
To develop a robust question-answer AI tool, it is important to divide your dataset into training and test sets. The training set is used to train the model on a large volume of labeled question-answer pairs, enabling it to learn patterns and understand the context. The test set is then used to evaluate the model's performance and measure its accuracy in providing correct answers. Careful selection and preparation of these sets contribute to the overall effectiveness of your custom model. - Model Architectures
Choosing the right model architecture is a critical aspect of building a custom self-trained question-answering model. Several architectures, such as Transformers, BERT (Bidirectional Encoder Representations from Transformers), or LSTM (Long Short-Term Memory), can be considered. Each architecture has its strengths and weaknesses, and selecting the most suitable one depends on factors like dataset size, complexity, and computational resources. Experimentation and testing are essential to determine the optimal architecture for your specific use case. - Training Process
Training your custom model involves feeding the training data through the chosen architecture and iteratively adjusting the model's parameters to minimize the loss function. This process involves optimizing hyperparameters, such as learning rate, batch size, and number of training epochs, to achieve the desired performance. Regular evaluation and monitoring during training help identify potential issues and allow for necessary adjustments to improve the model's accuracy. - Fine-Tuning and Iterative Improvement
As your custom model evolves, fine-tuning becomes a valuable technique to refine its performance. Fine-tuning involves updating the model using additional domain-specific or task-specific data. By incorporating new data and iteratively retraining the model, you can enhance its accuracy and adapt it to specific user requirements. This iterative improvement process allows your custom model to continuously learn and evolve, providing more accurate and reliable question-answering capabilities.
Conclusion
When building a question-answer AI tool, you have two main approaches: utilizing pre-trained models or developing a completely custom self-trained model. Pre-trained models offer a solid foundation, leveraging existing knowledge and fine-tuning capabilities. On the other hand, building a custom model provides the opportunity for complete customization and uniqueness. Assessing your project's requirements, available resources, and desired level of control will guide your decision. Whether you choose to utilize pre-trained models or build a custom model, the goal remains the same—to develop a question-answer AI tool that effectively addresses your specific needs and enhances user experiences.
Let's Dive In — Contact Us to Learn More
If you identify any mistakes in the article, kindly inform us so that we can rectify them


